跨越语言鸿沟:DeepThink多语种竞赛全解析与科研加速逻辑
2025年盛夏,我第一次系统测试GeminiDeepThink的多语言推理能力时,屏幕上跳出的成绩单让我愣了整整三秒。日语JMOFinals满分,ICPC亚洲日本初赛满分,法语竞赛同样100%通过——这不是单点突破,而是一场静默的能力重构。
从IMO金牌到八语种全覆盖:能力演进的时间线
回溯这条演进曲线,2025年7月是第一个关键节点。DeepThink首次在国际数学奥林匹克达到金牌标准,42分拿下35分。同期的ICPC世界决赛也取得类似高水平表现。这两个成绩随后被写进DeepMind官方博客,成为DeepThink迈过「世界级竞赛门槛」的标志性事件。
2026年2月,Google连发三篇博客,将DeepThink定位成「人类智力倍增器」。随后的升级版交出了一串硬指标:Humanity'sLastExam无工具辅助达48.4%,ARC-AGI-2官方验证达84.6%,Codeforces竞赛编程Elo评分3455,2025国际物理奥赛和化学奥赛笔试部分达到金牌水平。这条路线非常清晰:先用IMO、ICPC证明推理能力,再用多语种、跨学科竞赛验证通用迁移性。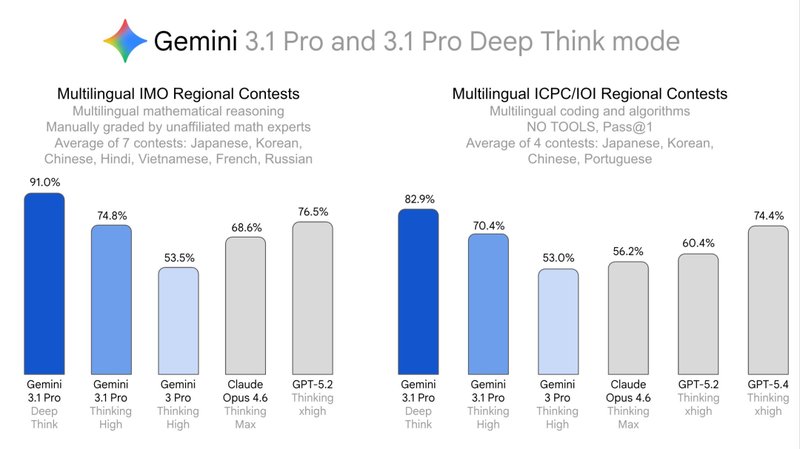
八张试卷的逐项拆解:数学与信息学的边界划定
把成绩单摊开来看,日语赛道最亮眼。2025年第35回日本数学奥赛本选满分,ICPC亚洲日本初赛满分,JMO本选甚至超过当届最高得分的80%水准,达到「金奖相当」标准。法语句子同样满分。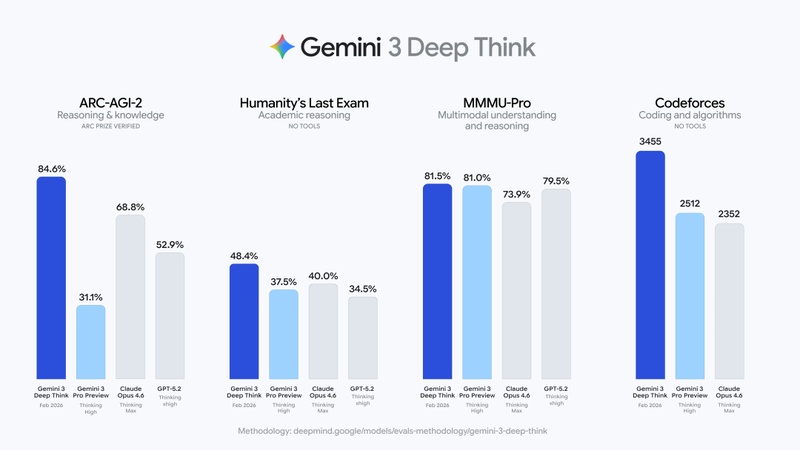
中文赛道的数据最有分析价值。第41届中国数学奥林匹克拿到86.3%,但信息学奥赛只有63.3%。这个落差画出了AI推理能力的真实边界:数学竞赛面对的是抽象推导、证明构造和多步演绎,这恰好是DeepThink最擅长的能力带;而信息学竞赛要求的不只是「想明白」,还包括把逻辑翻译成可执行代码、控制边界条件、兼顾复杂度约束——前者接近纯推理,后者要求「推理+算法设计+工程化实现」同时过关。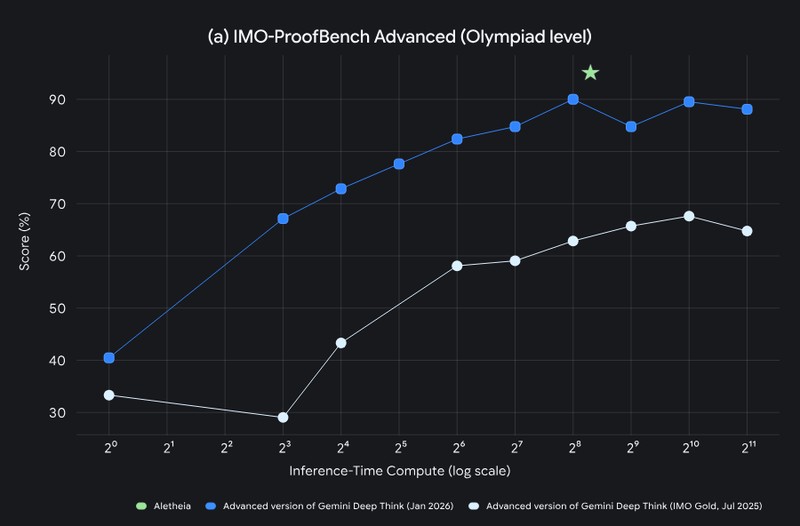
评测透明度与数据可信度:必须正视的缺失
但这份成绩单存在关键缺失:所有数据来自Google内部评测,没有第三方独立复现,没有竞赛官方认证,评测方法未公开。每道题做一次还是多次取最优?推理时用了多少算力?有没有人工提示工程介入?这些细节全部缺失。更重要的是,所有考试都是各国区域选拔赛而非国际决赛,难度差距不是一个量级。目前这仍然像一张由考生自己打分、自己公布、尚未交给教务处盖章的成绩单。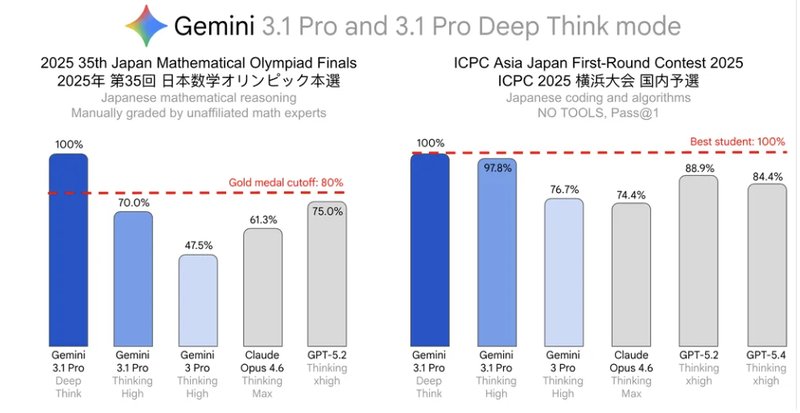
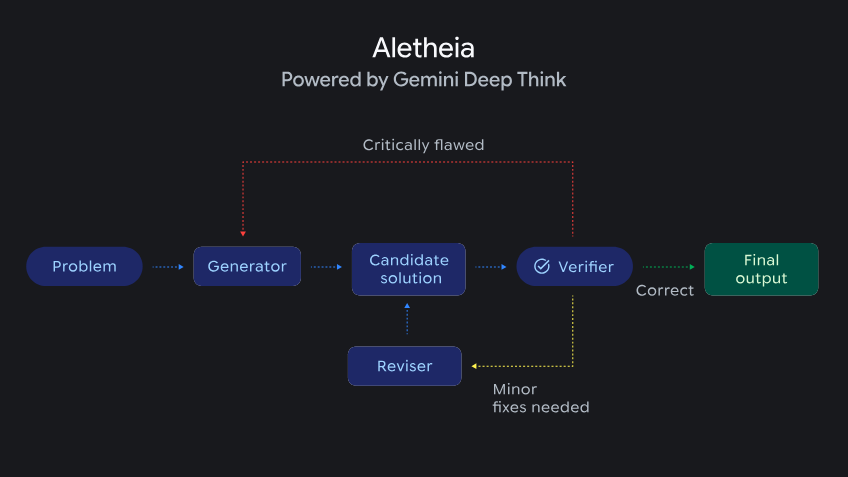
多语言科研公平性的工程化路径
Google选择8种语言不是随机行为。日语、韩语、中文覆盖东亚科研重镇,印地语、越南语覆盖新兴市场,法语、俄语、葡萄牙语覆盖欧洲和南美。加在一起,这是全球科研产出的大半壁江山。当竞品还在卷英文benchmark排行榜时,Google已在「AI科研加速器」领域开辟新战场。DeepThink的Aletheia数学研究智能体已参与产出多篇论文,在700个开放数学问题的半自主评估中独立解决了4个此前未解难题。这件事最重要的信号不是分数,而是AI科研工具的语言壁垒正在被当作工程问题来解决。如果这条路走通,全世界用日语、韩语、中文、印地语做研究的科学家,将第一次和英语母语者站在同一条起跑线上。